This is a complex post, so don’t jump to any conclusions.
Two weeks ago (gad, was it that long?) I asked you to think about something for a few days:
Imagine that for all your life, and your parents’ lives, your money had been managed by other people who had extensive training and licensing. Imagine that all your records were in their possession, and you could occasionally see parts of them, but you just figured the pros had it under control.
Imagine that you knew you weren’t a financial planner but you wanted to take as much responsibility as you could – to participate. Imagine that some money managers (not all, but many) attacked people who wanted to make their own decisions, saying “Who’s the financial planner here?”
Then imagine that one day you were allowed to see the records, and you found out there were a whole lot of errors, and the people carefully guarding your data were not as on top of things as everyone thought.
Two weeks before that post, I’d had a personal breakthough in my thinking. For a year I’d been a rabid enemy of Google Health, but now I said: I’m putting my data in Google and HealthVault: “I’m concluding that we can do more good by aggregating our data into large, anonymized databanks that smart software can analyze to look for patterns. Early detection means early intervention means fewer crises.” And I observed that the power of Web 2.0 “mash-ups” …
…lets people create software gadgets without knowing how they’ll be used, it lets people build tools that use data without knowing where the data will come from, and it lets people build big new systems just by assembling them out of “software Legos.”
So, I said, “I’m in.” I decided to punch the big red button and copy my personal health data into Google Health. What happened is the result of PatientSite’s “version 1” implementation, not their eventual full implementation, of the interface. To my knowledge, zero or one other hospitals have any interface at all, and as I’ll say later, I’m not even sure how much of the Google Health side of the connection is complete. Nonetheless, what I learned about my own data was quite informative, and quite surprising. (I’ve discussed what follows with hospital staff; this isn’t gossip behind anyone’s back. IMO, empowered people don’t gossip, they communicate clearly and directly with the people involved.)
When Google Health launched last May, my hospital’s CIO blog said “we have enhanced our hospital and ambulatory systems such that a patient, with their consent and control, can upload their BIDMC records to Google Health in a few keystrokes. There is no need to manually enter this health data into Google’s personal health record, unlike earlier PHRs from Dr. Koop, HealthCentral and Revolution Health.” So I went into my patient portal, PatientSite, and clicked the button to do it. I checked the boxes for all the options and clicked Upload. It was pretty quick.
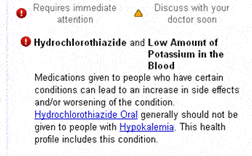
 But WTF? An alarm: “! Requires immediate attention” [see screen capture at right]
But WTF? An alarm: “! Requires immediate attention” [see screen capture at right]
Okay, yes, HCTz is my blood pressure medication. But low potassium? That was true when I was hospitalized two years ago, not now. What’s going on?
Then I saw the list of “conditions” it told Google I have. At left is a partial screen grab, and at right is the complete condition list that PatientSite transmitted: (Spoiler alert; this stuff is biological and might seem gross.)

Acidosis Anxiety Disorder Aortic Aneurysm Arthroplasty - Hip, Total Replacemt Bone Disease CANCER Cancer Metastasis to Bone Cardiac Impairment CHEST MASS Chronic Lung Disease Depressed Mood DEPRESSION Diarrhea Elevated Blood Pressure Hair Follicle Inflammation w Abscess in Sweat Gland Areas HEALTH MAINTENANCE HYDRADENITIS HYPERTENSION Inflammation of the Large Intestine Intestinal Parasitic Infection Kidney Problems Causing a Decreased Amount of Urine to be Passed Lightheaded Low Amount of Calcium in the Blood Low Amount of Potassium in the Blood Malignant Neoplastic Disease Migraine Headache MIGRAINES Nausea and Vomiting Nephrosis PSYCH Rash Spread of Cancer to Brain or Spinal Cord Swollen Lymph Nodes
Yes, ladies and germs, it transmitted everything I’ve ever had. With almost no dates attached. (It did have the correct date for my very first visit, and for Chest Mass, the x-ray that first found the undiagnosed lesion that turned out to be cancer. But the date for CANCER itself, the big one, was 5/25/07 – four months after the diagnosis. And no other line item had any date. For instance, the “anxiety” diagnosis was when I was puking my guts out during my cancer treatment. I got medicated for that, justified by the intelligent observation (diagnosis) that I was anxious. But you wouldn’t know that from looking at this.)
See how some of the listed conditions have links for More Info?  Let’s see, I was diagnosed with optical migraine. (I diagnosed myself, actually, by researching my symptoms and finding this illustrated site. That’s what e-patients do; it saves time in the doctor’s office… I brought a printout, with a dated list of episodes.) But optical migraine is not the impression you’d get from reading my Conditions list – in fact during my cancer workup one resident said “But you have headaches, right?” “No,” I said – “optical migraines, but without pain.” (Update 4/2: the illustration at left shows the dazzling pattern that an optical migraine produces.) So for that item in the conditions list, I clicked More Info. I didn’t get more info (i.e. accurate info) about my diagnosis, just Google’s encyclopedia-style article about migraines in general. (An optical migraine has little in common with migraines in general.)
Let’s see, I was diagnosed with optical migraine. (I diagnosed myself, actually, by researching my symptoms and finding this illustrated site. That’s what e-patients do; it saves time in the doctor’s office… I brought a printout, with a dated list of episodes.) But optical migraine is not the impression you’d get from reading my Conditions list – in fact during my cancer workup one resident said “But you have headaches, right?” “No,” I said – “optical migraines, but without pain.” (Update 4/2: the illustration at left shows the dazzling pattern that an optical migraine produces.) So for that item in the conditions list, I clicked More Info. I didn’t get more info (i.e. accurate info) about my diagnosis, just Google’s encyclopedia-style article about migraines in general. (An optical migraine has little in common with migraines in general.)
The really fun stuff, though, is that some of the conditions transmitted are things I’ve never had: aortic aneurysm and mets to the brain or spine. So what the heck??
I’ve been discussing this with the docs in the back room here, and they quickly figured out what was going on before I confirmed it: the system transmitted insurance billing codes to Google Health, not doctors’ diagnoses. And as those in the know are well aware, in our system today, insurance billing codes bear no resemblance to reality. (I don’t want to get into the whole thing right now, but basically if a doc needs to bill insurance for something and the list of billing codes doesn’t happen to include exactly what your condition is, they cram it into something else so the stupid system will accept it.) (And, btw, everyone in the business is apparently accustomed to the system being stupid, so it’s no surprise that nobody can tell whether things are making any sense: nobody counts on the data to be meaningful in the first place.)
It was around this time that I commented on Ted Eytan’s blog, “when you’re exporting to a new system, the rule is, Garbage Out, Garbage In. (Hint: visibility into the data in your old system may leave you aghast.)” We could (and will someday) have a nice big discussion about why the hell the most expensive healthcare system in the world (America’s) STILL doesn’t have an accurate data model, but that’s not my point. We’ll get to that.
And now we get to why I said, at the outset, don’t jump to conclusions. I’m mildly bitching about PatientSite, but that alone wouldn’t justify staying up to 3 in the morning all night writing a 2800 3500 word post; that one system isn’t a big deal for e-patients everywhere. (And besides, although PatientSite is old and clunky, a 1999 system if I ever saw one, it beats what most hospitals offer, and it did the job very well for me during my illness. And this is just version 1 of the interface; the current folly is not a permanent situation.)
The BIG question is, do you know what’s in your medical record? And THAT is a question worth answering. For every one of you.
See, every time I speak at a conference I point out that my 12/6/2003 x-ray identified me as a 53 year old woman. I admit I have the man-boob thing going on, but not THAT much. And here’s the next thing: it took me months to get that error corrected, because nobody’s in the habit of actually fixing errors. Think about THAT.
I mean, some EMR pontificators are saying “Online data in the hospital won’t do any good at the scene of a car crash.” Well, GOOD: you think I’d want the EMTs to think I have an aneurysm, anxiety, migraines and brain mets?? Yet if I hadn’t punched that button, I never would have known my data in the system was erroneous.
And this isn’t just academic: remember the Minnesota kidney cancer tragedy just a year ago, which arose at least partly out of an error that ended up in the hospital’s EMR system. Their patient portal allowed patients and family to view some radiology reports, but not the one that contained the fateful error.
The punch line came when I got over my surprise about what had been transmitted, and realized what had not: my history. Weight, BP, and lab data were all still in PatientSite, and not in Google Health. So I went back and looked at the boxes I’d checked for what data to send, and son of a gun, there were only three boxes: diagnoses, medications, and allergies. Nothing about lab data, nothing about vital signs.(So much for “no need to manually enter this health data into Google’s personal health record.”) And of the three things it did transmit:
- what they transmitted for diagnoses was actually billing codes
- the one item of medication data they sent was correct, but it was only my current BP med. (Which, btw, Google Health said had an urgent conflict with my two-years-ago potassium condition, which had been sent without a date). It sent no medication history, not even the fact that I’d had four weeks of high dosage Interleukin-2, which just MIGHT be useful to have in my personal health record, eh?
- the allergies data did NOT include the one thing I must not ever, ever violate: no steroids ever again (e.g. cortisone) (they suppress the immune system), because it’ll interfere with the immune treatment that saved my life and is still active within me. (I am well, but my type of cancer normally recurs.)
In other words, the data that arrived in Google Health was essentially unusable.
And now I’m seeing why, on every visit, they make me re-state all my current medications and allergies: maybe they know the data in their system might not be reliable.
Hey wait, a new article in the Archives of Internal Medicine (co-authored by our own Danny Sands, my very own primary) says Clinicians override most medication alerts. Could it be they’ve been through this exercise themselves, and they consider the data unreliable? (Or do they just not trust computers?) (Hey Pew Internet, wanna check for generational differences?) Who knows, perhaps the resident in the migraine story has learned early on that the data in his system is not to be taken at face value – I don’t know.
In any case, my hospital is very proactive and empowering to staff about root cause analysis for failures, with its “SPIRIT” program, and they’ll add any process or form that can catch potential errors. That’s good. But wait: On numerous visits, I’ve restated on those forms “no steroids.” But evidently what I write on the forms never gets entered into the system. Hm.
I work with data in my day job. (I do marketing analytics for a software company. We import and export data all the time.) I understand what it takes to make sure you’ve got clean data, and make sure the data models line up on both sides of a transfer. I know what it’s like to look at a transfer gone bad, and hunt down where the errors arose, so they don’t happen again. And I’m fairly good at sniffing out how something went wobbly.
And you know what I suspect? I suspect processes for data integrity in healthcare are largely absent, by ordinary business standards. I suspect there are few, if any, processes in place to prevent wrong data from entering the system, or tracking down the cause when things do go awry.
And here’s the real kicker: my hospital is one of the more advanced in the US in the use of electronic medical records. So I suspect that most healthcare institutions don’t even know what it means to have processes in place to ensure that data doesn’t get screwed up in the system, or if it does, to trace how it happened. Consider the article in Fast Company last fall, about an innovative program at Geisinger. Anecdotally, it ended with this chiller:
“… a list of everybody that accessed the medical record from the time he was seen in the clinic to two weeks post-op.’There were 113 people listed — and every one had an appropriate reason to be in that chart. It shocked all of us. We all knew this was a team sport, but to recognize it was that big a team, every one of whom is empowered to screw it up — that makes me toss and turn in my sleep.”
In my day job, our sales and marketing system (Salesforce.com) has very granular authorizations for who can change what, and we can switch on a feature (at no extra cost) to track every change that’s made on any data field. Why? Because in some business situations it’s important to know where errors arose – an error might cause business damage, or an employee might sue over a missed quota.
So I’m thinking, why on earth don’t medical records systems have these protections? If a popular-priced sales management system has audit traces, to prevent an occasional lawsuit over a sales rep’s missed commission, why isn’t this a standard feature in high-priced medical records systems? In any case, in the several weeks since these discoveries started, as far as I know they haven’t figured out how my wrong data got in there. And without knowing how the wrong data got in, there’s not a prayer of identifying what process failed.
BUT AS I SAID, this is not about my hospital; a problem at my hospital affects only one scrillionth of patients in the US, not to mention the rest of the world. And please don’t blame my hospital’s CIO; I think what he wrote about the Google Health interface was overzealous, but I believe he’s a good man, committed to helping us own our own data (his work on the Google Health advisory board was unpaid), and this post isn’t about him: as far as I know, this hospital is farther along than anyone else: hardly anyone else has implemented a Google Health interface. (Perhaps for good reason.) Nor is this a slam on Google Health.I haven’t probed yet into whether there are limitations in what it does; might be fine, might not. Heck, neither PatientSite nor I have put any good data into it yet. (And I haven’t even touched HealthVault.) None of that is my point. Rather, my point is about the data that was already in my PHR, uninspected. For that, let’s return to my previous post:
Then imagine that one day you were allowed to see the records, and you found out there were a whole lot of errors, and the people carefully guarding your data were not as on top of things as everyone thought.
In my day job, when we discover that a data set has not been well managed, we have to make a decision: do we go back and clean up the data (which takes time and money), or do we decide to just start “living clean” from now on? My point, my advice to e-patients, is:
- Find out what’s in your medical record. What’s in your wallet, medically speaking? Better find out, and correct what’s wrong.
- Get started, manually, moving your data into Google Health, HealthVault, or some such system. I’ve heard there are similar PHR systems (personal health records), not free but modestly priced, that can reportedly make this easier. I’m sure their friends will show up here in the comments. (Feel free to post product info links in the comments, everyone.)
- Let’s start working, now, on a reliable interoperable data model. I know the policy wonks are going to scream “Not possible!” and I know there are lots of good reasons why it’s impossibly complex. But y’know what else? I’ve talked to enough e-patients to be confident that we patients want working, interoperable data. And if you-all in the vendor community can’t work it out, we will start growing one. It won’t be as sophisticated as yours, but as with all disruptive technologies, it will be what we want.And we’ll add features to ours, faster than you can hold meetings to discuss us.I have to say, while researching this post I was quite surprised at how very, very far the industry has to go before reaching a viable universal data model. New standards are in development, but I’m certain that it will take years and years and gazillions of dollars before any of that is a reality. (What, like costs aren’t high enough already?) In the meantime, your data is probably not going to flow very easily from system to system. Far, far harder than (for instance) downloading your data to Quicken from different credit card companies and banks. (Wizards and geeks refer to this “flow” issue as “data liquidity.” We’ll talk about that in the future.)
- Let’s start working, now, on an open source EMR/PHR system. The open source community creates functionality faster, and more bug-free, than commercial vendors do – and nobody can latch onto proprietary data in such systems to milk more margin out of us… because it ain’t proprietary.The great limitation of open source is that it’s generally not well funded. But you know what? Every person in America (including software engineers) is motivated to have good reliable healthcare systems, and I assert that the industry ain’t getting’ it done on their own. As I said in my Thousand Points of Pain post (cross-posted on IBM’s Smarter Planet blog as A business thinker asks, what will it take to get traction?), it’s fine with me if industry vendors come along too – but I would not stake my life on their moving fast enough for my needs. Or your mother’s needs.
Want a case study with real consequences? Recall what happened last year to famed Linux guru Doc Searls when he couldn’t read his own scan data, because good cross-platform image viewing tools weren’t available. (His prescription: the patient should be the platform and “the point of integration.”) Well, okay, so Doc was a year ahead of me. I’m catching on. This illustrates why I think people from outside the profession may be our greatest asset in building what patients really need: patients tend to build what they want. And we who work with data all day know that these problems are not unsolvable.
My bottom line: I think we ought to get our data into secure online systems, and we shouldn’t expect it to happen with the push of a button. It’ll take work. So let’s get to work. You know the work will be good for you, and heaven only knows what you’ll learn in the process. You’ll certainly end up more aware of your health data than when you started. And that’s a good thing.
Minor edits made 4/12/2009, and 1/5/2012 and 9/19/2022 for clarity and to adjust to this blog’s new format





What you don’t realize is that there is another kind of data that you don’t see in your health record, called physician’s notes. This is where your physician inserts his/her comments about what he/she actually thinks what is wrong with you and what to do about it. You don’t get this because the candid opinion of the doctor may not be very comfortable for you to read and might result in a suit or at least unneeded argument. The billing codes, which as you observe, have little relation to reality, are used to list the possible worst thing that might be wrong with you which the consult/test can then dismiss in most cases. As long as you stick with the same health care delivery system it’s members know more about your reality than the billing codes would suggest. As always, there is more to the story than you might think.
Hi Wendell – yes, things have moved forward a lot since this April 2009 post. See this month’s post on the OpenNotes program.
Nothing has really changed in the past 12 years! This article could have been written last week. No true interoperability yet. No universal data model. No reliable data integrity processes. No consistent audit trail. No push button simplicity. As both physician and patient, it drives me nuts that these critical issues have not been solved. So I spearheaded development of an iOS platform that lets people like us organize their own medical information into a state-of-the-art mobile application. It is called Tidy Health PHR and is available for free on the App Store. It is starting to get some traction with over 20,000 active users and lots of great feedback that lets us iterate often to produce a personal health record that is actually reliable and easy to use. I hope ePatient Dave’s fans give it a try and help us make Tidy app the best mobile PHR possible.